Khi tạo ảnh từ AI, không ít lần các bạn gặp các biến dạng từ người cho đến phong cảnh không mong muốn, hãy tìm cách khắc phục chúng trong các phương pháp mình đưa ra dưới đây
Trong bài viết, mình sẽ phân loại các lỗi thường gặp và các xử lý của các lỗi này.
![]() . LỖI VỀ GIẢI PHẪU HỌC CƠ THỂ (ANATOMY)
. LỖI VỀ GIẢI PHẪU HỌC CƠ THỂ (ANATOMY)
Lỗi giải phẫu học cơ thể được hiểu khi chủ thể là người bạn tạo ra trong ảnh của bạn không giống người bình thường dù không cố ý. Thường chúng ta sẽ thấy các lỗi này biểu hiện là thừa chân tay, chân tay thừa, thiếu ngón, mặt méo mó, người quá dài,…

Dưới đây là một số gợi ý để chỉnh sửa những lỗi sai này:
1. Kiểm tra lại kích cỡ size ảnh của bạn
Không phải tự nhiên size ảnh mặc định của Stable Diffusion là 512 x 512. Đây là size ảnh phổ biến để đào tạo các model. Điều này có nghĩa là các bức ảnh tạo ra với kích cỡ này sẽ được “hiểu” dễ hơn là những kích cỡ khác; đặc biệt là các kích cỡ quá khổ như quá dài hay quá rộng hoặc quá lớn.
Như vậy nên bắt đầu bằng các kích thước tiêu chuẩn như 512 x 512 hoặc 512 x768, sau đó sử dụng các phương pháp như outpaiting, crop, upscale để đạt được bố cục như mong muốn.
2. Sử dụng Negative Prompt
Được hiểu là các từ khóa mà bạn không muốn xuất hiện trong bức ảnh, thêm nó vào negative prompt, nó sẽ hạn chế được các lỗi cơ thể cho bạn.
Một số từ khóa mọi người hay sử dụng bao gồm:
Inaccurate anatomy, unrealistic proportions, poorly defined muscles, amateurish rendering, low resolution, grainy texture, distorted facial features
3. Sử dụng Textual Inversion / Lora
Một cách mạnh mẽ hơn để yêu cầu Stable Diffusion không tạo ra ảnh lỗi là đưa một lượng data bắt buộc vào thông qua textual Inversion hoặc Lora.
Bạn chỉ đơn giản là tải các Textual hoặc Lora cần thiết và đưa vào prompt. Dưới đây là một số textual inversion phổ biến

4. Sử dụng Upscale method
Đôi khi việc ảnh bị méo mó đơn giản là vì bức ảnh không đủ dữ liệu hay độ phân giải. Việc upscale lên độ phân giải lớn hơn sẽ giải quyết vấn đề này.
Để tìm hiểu về cách tăng cường độ phân giải, hãy xem
From Zero to Hero (P6): Extra - Nâng cấp chi tiết bức ảnh của bạn bằng các phương pháp Upscale
5. Sử dụng Adetailer
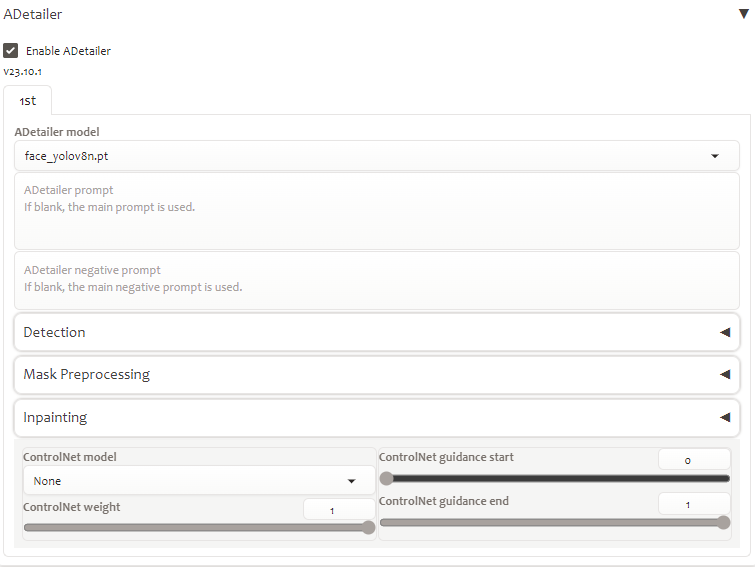
Adetailer có thể được hiểu là bạn kích hoạt một bước nữa sau khi tạo ảnh, AI sẽ tự nhận một số đặc điểm cơ thể như mặt, tay, chân,… để sửa lại một lần nữa và đa phần sẽ xử lý tốt hơn.

Cách mà Adetailer nhận biết người - khuôn mặt

Trước và sau khi dùng Adetailer
6. Sử dụng inpainting
Đây là phương án khó nhất nhưng cũng là phương án toàn vẹn nhất để sửa các lỗi giải phẫu học.

Phương án này là phương pháp nâng cao sử dụng để các lỗi khó như bàn tay dị tật.
Để tìm hiểu thêm về phương án này, hãy đọc Chỉnh sửa lỗi tay do ảnh tạo từ AI
![]() CÁC LỖI DO TỪ KHÓA
CÁC LỖI DO TỪ KHÓA
- Khi mô tả prompt, rất có khả năng những từ khóa bạn mô tả trong prompt sẽ không được thể hiện hoặc thể hiện không chính xác. Vấn đề này xảy ra bởi vì việc đọc hiểu của AI rất khác người bình thường.
Xem xét ví dụ dưới đây
Prompt: Character of the game, villainess Annie is a child firemage with immense pyromantic power, summoning of her beloved massive scale teddy bear Tibbers, as a fiery guardian. Portrait by Gustave Moreau, Thomas Kinkade, James Gurney. Carne Griffiths. Frank Frazetta. Alberto Seveso, oil paint, masterpiece, Realistic, deep colors, Field, Intricate, detailed, sharp, clear, Perfect face, Red hair, Focus on the face, clear eyes.
Neg Prompt: blurry, abstract, disfigured, bad art, deformed, poorly drawn, extra limbs, close up, b&w, weird colors, blurry, watermark, 2 heads, long neck, watermark, elongated body, cropped image, out of frame, draft, deformed hands, twisted fingers, double image, malformed hands, multiple heads, extra limb, ugly, poorly drawn hands, missing limb, cut-off, over satured, grain, low resolution, bad anatomy, poorly drawn face, mutation, mutated, floating limbs, disconnected limbs, out of focus, long body, disgusting, extra fingers, gross proportions, missing arms, mutated hands, cloned face,blur haze

Như vậy chú "massive scale teddy bear" hoàn toàn không xuất hiện. Điều này là do GIỚI HẠN CỦA PROMPT làm cho nó không thể hiểu được ý nghĩa của ngữ cảnh câu đó. Để khắc phục chúng ta cần biết kết hợp các các trọng số của prompt ( keyword’s weight), controlnet,…
- Một vấn đề nữa khi sử lora trong prompt là trọng số của lora. Một lora có khả năng thay đổi từ “-5” đến “+5” (dấu âm là tác dụng ngược). Tuy nhiên mỗi Lora có 1 khoảng hiệu quả nhất định, ngoài khoảng hiệu quả đó, lora sẽ phản tác dụng là ảnh tạo ra rất méo mó. Để biết được các sử dụng mỗi lora nhất định, hãy tham khảo các ví dụ của creator.

Lora Shizuka Masou được sử dụng với các weight khác nhau, ta có thể thấy khoảng hiệu quả sẽ từ 0.5 đến 1.
- Sử dụng đúng Checkpoint
Mỗi lora chỉ được train với một số checkpoint nhất định, vì vậy khi sử dụng 1 lora nào đó, bạn phải kiểm tra xem Lora đó được sử dụng với model/ CP nào, việc dùng sai sẽ dẫn đến sự không hiệu quả, hoặc đổ vỡ hoàn toàn.

Sử dụng cùng 1 prompt giống nhau với lora 3D rendering . Chỉ có model có dữ liệu training đúng mới ra được ảnh như mong muốn (bên phải)
![]() CÁC LỖI DO VIỆC CÀI ĐẶT
CÁC LỖI DO VIỆC CÀI ĐẶT
-
VAE
Khi bạn thấy bức ảnh tạo ra sự mờ nhạt không cải thiện, việc đầu tiên hãy đến bạn đang thiếu VAE
Việc bổ sung VAE sẽ giúp bức ảnh tươi tắn và có nhiều sức sống hơn. -
Lỗi AttributeError: ‘NoneType’ object has no attribute ‘mode’

Lỗi này khá phổ biến với nhiều người, tuy không có một lí do cố định nhưng được hiểu là bạn đang thiếu đầu vào cho một mục nào đấy. Hãy chắc chắn là tất cả các extension mà bật lên đã có input, nếu lỡ bật nhầm 1 extension nào lên hãy tắt đi và generate lại.
3. Lỗi CUDA out of memory
Lỗi này thường xảy ra khi tác vụ của bạn sử dụng quá sức khả năng của VRAM, thường là do chạy video hoặc render quá nhiều hình môt lúc. Hãy thử các tác vụ nhẹ nhàng hơn, hoặc chuyển đến một cấu hình Kaikun mạnh hơn.
4. Lỗi “Runtime Error: mat1 and mat2 shapes cannot be multiplied…”
Lỗi này hay xảy ra với người dùng sử dụng controlnet. Nguyên nhân thường là do model controlnet không phù hợp với model của Stable Diffusion, thử đổi model và thử lại
Một số người sử dụng gặp lỗi này khi bật hires.fix
5. Lỗi “TypeError:expected Tensor as element 0 in argument 0, but got dict/nonetype/…”
Theo mình tìm hiểu các lỗi này xuất phát từ Pytorch (code của Stable Diffusion) và không có cách giải quyết triệt để cho vấn đề này. Thường thì cập nhật phiên bản sẽ giúp giải quyết
6. Lỗi “NansException: A tensor with all Nans was produced in Unet. This could be either because there’s not enough precision to represent the picture, or because your video card dose not support half type…”
Lỗi này xảy ra khi mọi người dùng img2img. Đây cũng là một code lỗi từ stable diffusion. không rõ vì sao có lỗi này nhưng có một số phương pháp sửa sau đây
Setting → Stable Diffusion → Maximum number of checkpoints loaded at the same time, chọn 2 checkpoint thay vì 1.
Bỏ chọn “Upcast cross attention layer to float32” trong Stable Diffusion
“Settings → Optimization → Cross attention optimization → sdk-no-mem -scaled dot product without memory efficient attention”
Một cách khác là hãy tạo 1 ảnh txt2img với prompt rỗng rồi sau đó tạo ảnh img2img
![]() Lỗi không tương thích model
Lỗi không tương thích model
Hiện giờ SD đã có rất nhiều biến thể như Sd 1.5; SD 2.1, SDXL, SDXL turbo, SDXL Lighting,… và đặc điểm của các model này là chưa tương thích với nhau.

Một lỗi rất phổ biến người mới hay gặp phải là dùng Lora không tương thích với model, khi tải lora sdxl về nhưng model các bạn để model SD 1.5 thì UI của A1111 sẽ không hiện ra, hãy lưu ý.
Chúc mọi người thành công!