Xin chào người sử dụng KaiKun AI! ![]()
![]()
Việc phát triển rất nhanh của AI đã giúp cho việc tạo ra video từ text hoặc video to video đã trở nên dễ dàng hơn bao giờ hết.
Hôm nay mình xin giới thiệu một công cụ mạnh nhất hiện nay, có sức hút, số lượng người ưa chuộng đông đảo, AnimateDiff.


Trong bài viết, mình sẽ hướng dẫn cụ thể các tạo ra ảnh động (gif), video từ tất cả các chức năng có trên phiên bản AnimateDiff Web Ui.
Để biết thêm về dự án, hãy xem trên AnimateDiff
![]() Thông số kỹ thuật
Thông số kỹ thuật ![]()
Dưới dây là bảng thông số kỹ thuật tích hợp sẵn của AnimateDiff vào Kaikun
Các thông số được giới thiệu từ trên xuống dưới giúp bạn dễ quan sát
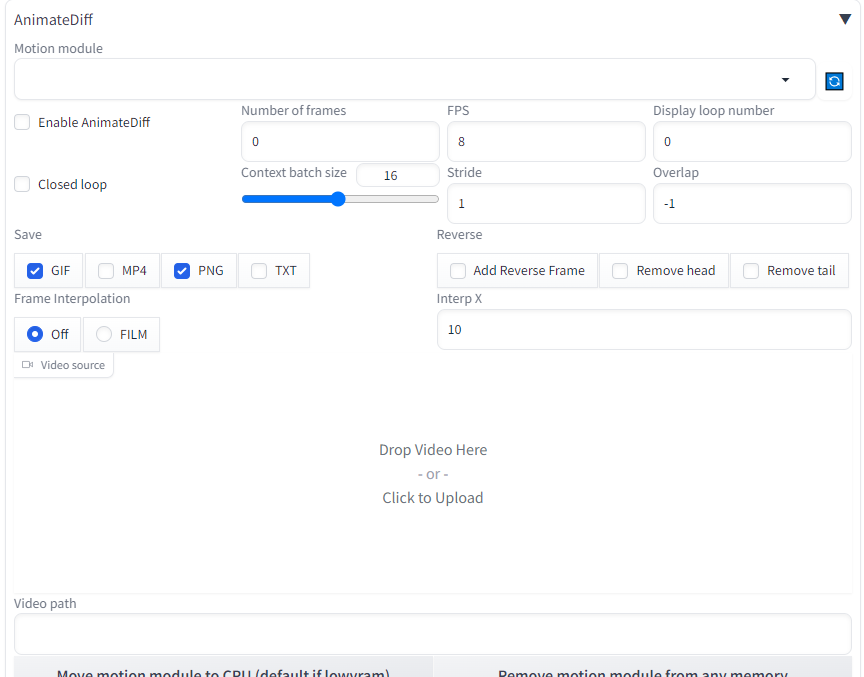
Motion Module: Các dữ liệu được training phục vụ cho việc tạo ra chuyển động, hiện đã có cả module SD 1.5 và SD XL
Enable AnimateDiff: Bật /tắt ứng dụng ( nhớ tích khi sử dụng)
Close loop:Tạo ra vòng lặp vĩnh cửu với khung hình đầu giống khung hình cuối
N: cố gắng không tạo vòng lặp
R-P: Điều này có nghĩa là tiện ích mở rộng sẽ cố gắng giảm số lượng ngữ cảnh vòng lặp đóng, “prompt travel” sẽ không được cho phép trong phép nội suy
R+P: Điều này có nghĩa là tiện ích mở rộng sẽ cố gắng giảm số lượng ngữ cảnh vòng lặp đóng, “prompt travel” sẽ được cho phép trong phép nội suy
A: cố gắng tạo ra vòng lặp
Number of frames: Số lượng khung hình của toàn bộ video. Nếu để mặc định là 0, thì bạn phải thêm nguồn (video, video path, batch) cho ứng dụng, số lượng khung hình sẽ bằng số lượng source của bạn
FPS: Số lượng khung hình trên giây. Nếu có 16 khung hình và FPS = 8 thì thời lượng video/gif là 2s. Nếu bạn tải 1 video lên thì số khung hình trên giây sẽ lấy từ video gốc
Display loop number: Số lần GIF được phát lại phụ thuộc vào giá trị được chỉ định. Giá trị 0 có nghĩa là GIF sẽ không bao giờ dừng lại và tiếp tục phát lại liên tục.
Context batch size: Số khung hình được truyền vào mô-đun chuyển động cùng một lúc, giá trị này phụ thuộc vào mô-đun cụ thể được sử dụng. Model SD1.5 được đào tạo với 16 khung hình, vì vậy nó sẽ cho kết quả tốt nhất khi số khung hình được đặt là 16. Model SDXL HotShotXL được đào tạo với 8 khung hình thay vì 16. Chọn [1, 24] cho mô-đun chuyển động V1 / HotShotXL và [1, 32] cho mô-đun chuyển động V2.
Stride: Giá trị tối đa của bước nhảy mà model sẽ sử dụng để xử lý. Mặc định “1” là hoàn toàn không có vòng lặp xử lý. Nếu giá trị là 2 có nghĩa là quá trình phân tích chuyển động sẽ bỏ qua mọi khung hình thứ hai. Nếu được đặt là 3, nó sẽ bỏ qua mọi khung hình thứ ba.
Overlap: Số khung hình chồng nhau trong ngữ cảnh. Mặc định là không thì số khung hình chồng nhau = Context batch size / 4
Save: Lưu file các định dạng có sẵn
Frame interpolation: Nội suy khung hình - Nội suy giữa các khung hình với việc triển khai FILM của Deforum. Yêu cầu sử dụng tiện ích Deforum mở rộng.
Video source/ Video path: Đường dẫn của video làm nguồn cho xử lý của ứng dụng
Reverse: Đảo ngược chuyển động, đưa khung hình đầu, hoặc cuối ra khỏi chuỗi chuyển động
Interp X: Nội suy X lần từ video gốc. Ví dụ x =2 , video gốc có FPS = 8, thì kết quả sẽ có FPS = 8 x 2 =16
![]() Ứng dụng thực tế
Ứng dụng thực tế
![]() txt2img
txt2img
Vào tab txt2img, sử dụng prompt mẫu sau
Prompt: girl, cosmic, otherworldly, mysterious, grim, haunting, Vibrant Rim Light, Eerie, unsettling, dark, spooky, suspenseful, grim, highly detailed, by Stefan Gesell
Neg: cheerful, bright, vibrant, light-hearted, cute, (worst quality:2), (low quality:2), easynegative
Model: toonyou_beta6
Dưới đây là thông số điều chỉnh animatediff
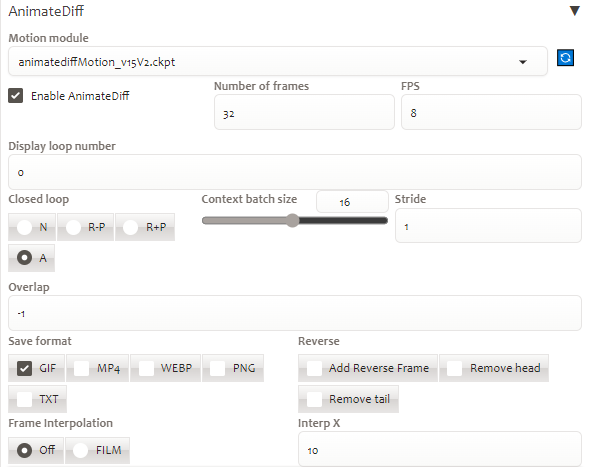
Dưới đây là kết quả

Quá hài lòng ![]()
![]()
![]() img2img
img2img
Bản chất của cách này là mình tạo ảnh txt2img rồi đẩy sang tab img2img
Prompt: masterpiece, concept art, mid shot, dynamic pose, centered, splash art, wukong king, (epic composition, epic proportion), Award Winning,
Neg: cheerful, bright, vibrant, light-hearted, cute, (worst quality:2), (low quality:2), By bad artist -neg
Kết quả từ txt2img, mình sẽ ấn chuyển sang img2img

Tại tab img2img cần phải chỉnh 2 lần bảng thông số lần lượt như sau
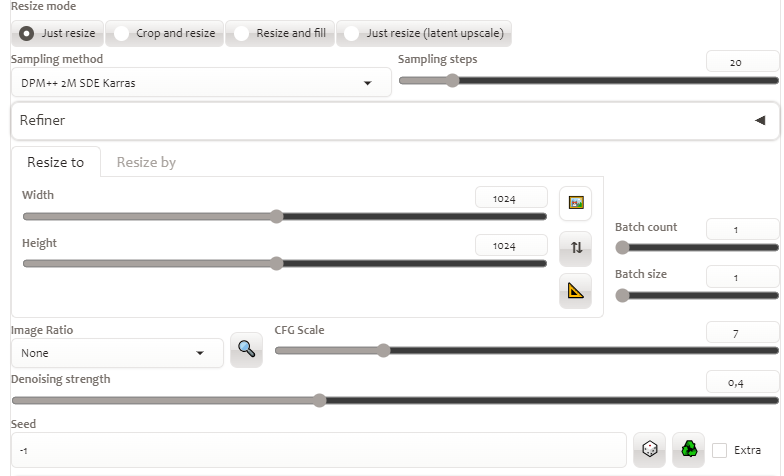
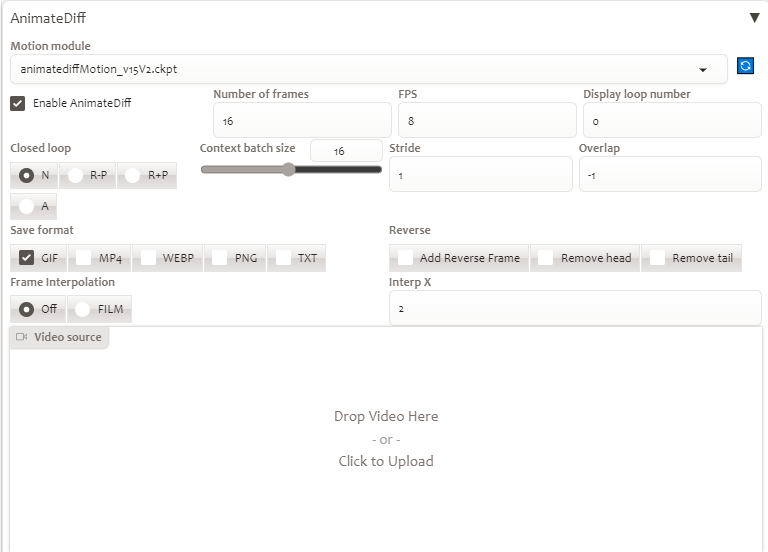
Ấn

Hiệu ứng bụi bay mù mịt khá ngầu nhỉ !!!
![]() Motion Lora
Motion Lora
Để có thể làm chuyển động mượt mà như dùng camera, bạn có thể thử lora motion.
Ở đây mình dùng lora zoom in
Prompt: Hyper realistic painting of a beautiful girl in an EVA plugsuit, hyper detailed, anime, by greg rutkowski, trending on artstation, lora:v2_lora_ZoomIn:0.65
Neg: nsfw, bright, vibrant, light-hearted, cute, (worst quality:2), (low quality:2), By bad artist -neg

![]() Prompt Travel
Prompt Travel
Đúng như cái tên, prompt của bạn sẽ di chuyển trong quá trình tạo
Cấu trúc có thể hiểu như sau:
Dòng đầu tiên là head prompt, có thể bỏ qua. Bạn có thể viết không/có một hoặc nhiều dòng head prompt.
Dòng thứ hai và thứ ba dùng cho prompt nội suy , theo định dạng “số khung hình: prompt”.
Số khung hình của bạn phải tăng dần, nhỏ hơn tổng số khung hình. Khung hình đầu tiên có chỉ số 0.
Dòng cuối cùng là teail prompt, có thể bỏ qua. Bạn có thể viết không/có một hoặc nhiều dòng tail prompt.
Cũng là prompt ở trên, nhưng mình sẽ đưa “Prompt travel” vào:
Hyper realistic painting of a beautiful girl in an EVA plugsuit, hyper detailed, anime, by greg rutkowski, trending on artstation
0: closed mouth
8: open mouth
smile

![]() Controlnet V2V
Controlnet V2V
Controlnet đã thực sự quá nhiều và quá phức tạp, giờ lại thêm video to video, animatediff thì đúng là mind blow ![]()
![]()
Thực sự việc sử dụng controlnet phải rất phụ thuộc vào trải nghiệm và trình độ mỗi người.
Bản chất mình sẽ đưa 1 video source vào để xử lý qua controlnet thành từng frame, và các frame này sẽ được xử lý và ghép lại thành video hoàn chỉnh nhở animatediff
Ứng dụng của khả năng này là rất nhiều, các bạn có thể thấy rất nhiều video tương tự trên mạng. Để video kết quả có thể sát nhất được với video gốc cần sử dụng nhiều controlnet kết hợp. Việc chạy tác vụ chắc chắn sẽ dẫn đến việc xử lí rất lâu của hệ thống. Vì vậy khi sử dụng controlnet v2v, mình rất khuyến nghị máy có cấu hình cực cao hoặc nâng cấp server cấu hình cao trên Kaikun từ RTX 4090 trở lên.
Ở đây mình chọn 1 video đầu vào và điều chỉnh thông số bên dưới chỉ mang tính chất tham khảo:
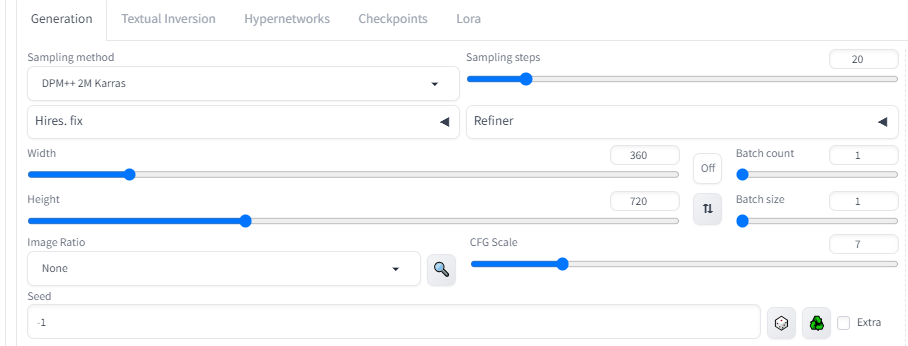
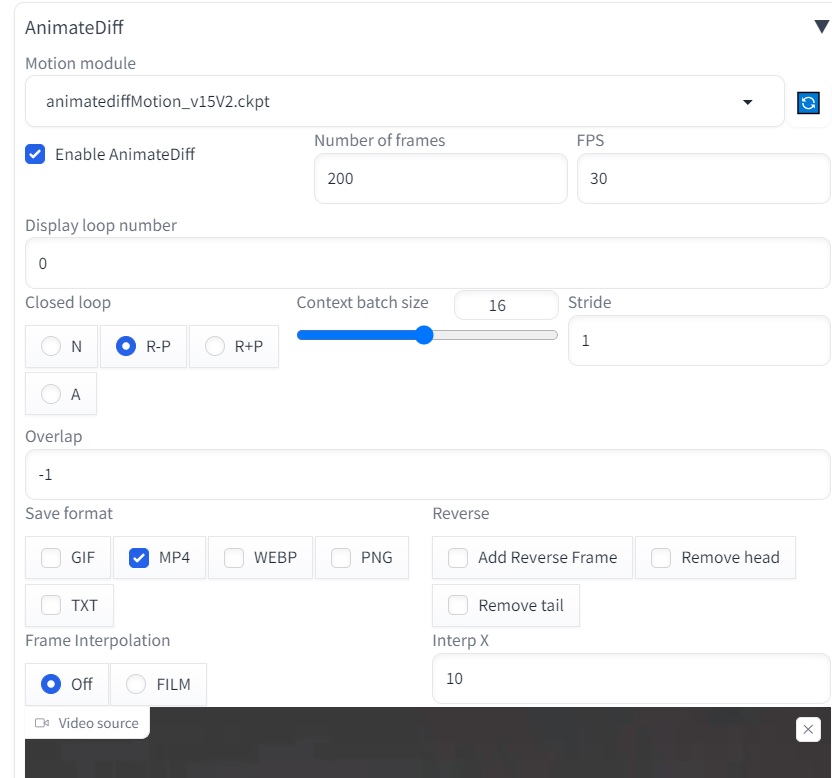
và để 2 controlnet là openpose và normalbae:
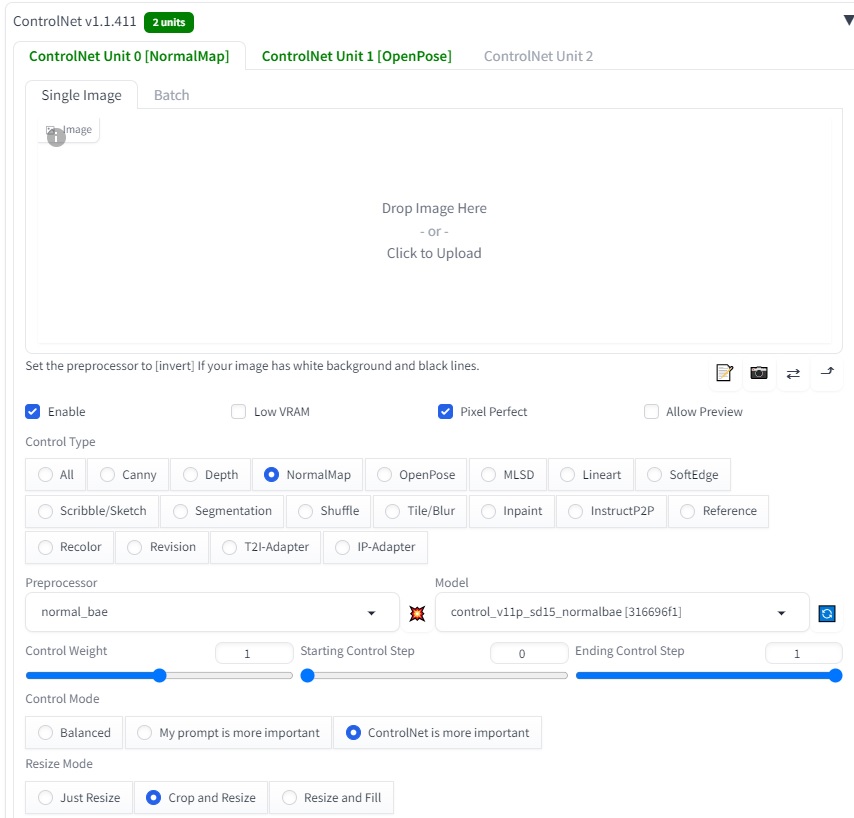
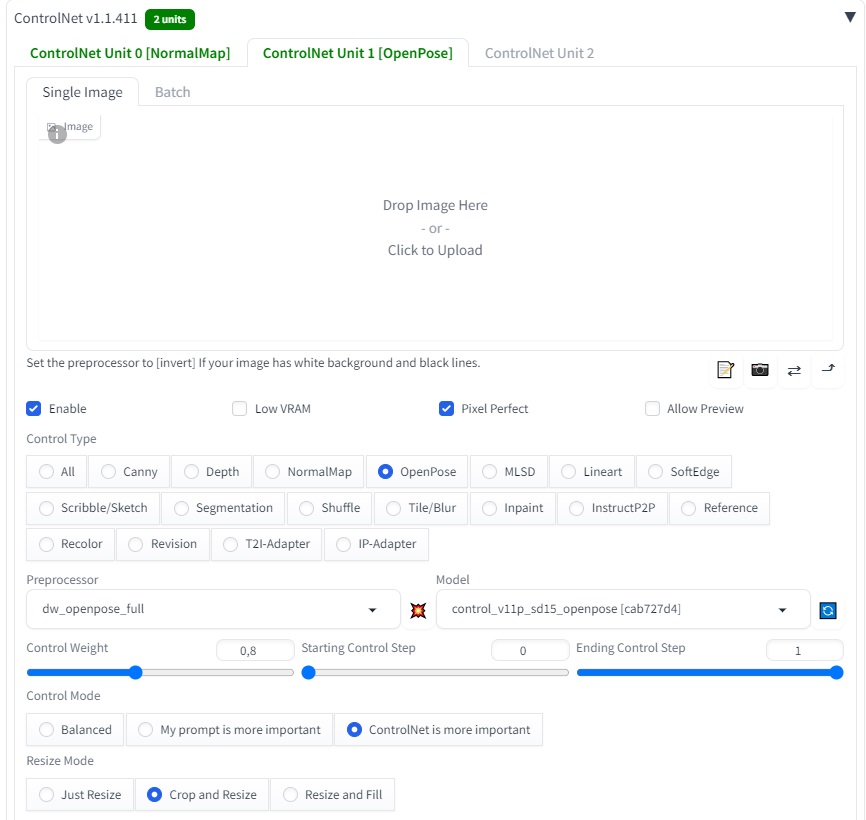
Ấn generate và chờ đợi ![]()
Các bạn sẽ thấy các khung hình đưa vào controlnet như dưới đây là đúng
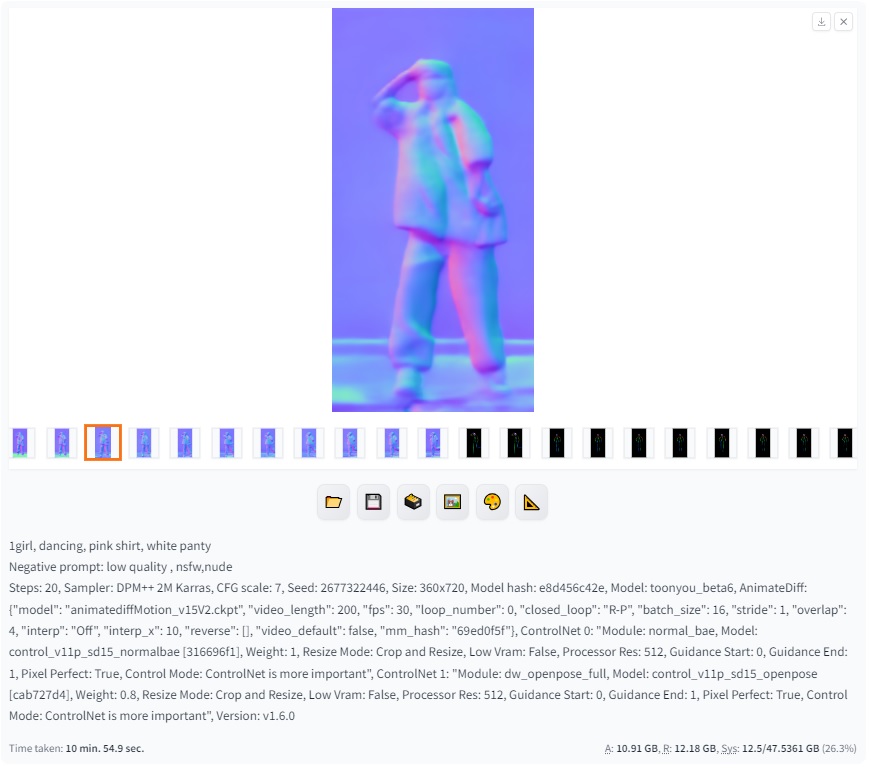

Kết quả cuối cùng:

Chúc các bạn thành công !
Viết bài này xong muốn sụn cái lưng, mọi người like ủng hộ mình phát :**