Stability AI chính thức ra mắt phiên bản “Stable Video Diffusion”, một AI có khả năng tạo ra video từ text và Images.

Stability AI, công ty phát triển AI vô cùng nổi tiếng ‘Stable Diffusion,’ đã phát hành ‘Stable Video Diffusion,’ vào ngày 11/21, một mô hình tạo và xử lý video có thể tạo ra video độ phân giải cao từ văn bản và hình ảnh.

Giới thiệu về Stable Video Diffusion

Stable Video Diffusion: Mở rộng Mô hình Phân tán Video cho Các Bộ Dữ liệu Lớn - Stability AI
Stable Video Diffusion ra mắt hiện tại như một phiên bản nghiên cứu và mã nguồn mở GitHub.
GitHub - Stability-AI/generative-models: Các Mô hình generative Stability AI
Bạn cũng có thể kiểm tra các trọng số cần thiết để chạy mô hình cục bộ trên HuggingFace ở dưới đây.
Stable Video Diffusion được phát hành trong hai mô hình Chuyển đổi Hình ảnh sang Video có thể tạo ra loại 14 khung hình và 25 khung hình, cho phép video với tốc độ khung hình tùy chỉnh từ 3fps đến 30fps.
Nếu bạn nhập ‘Ice dragon in the mountains’, đoạn hoạt hình chính xác được tạo ra như sau.

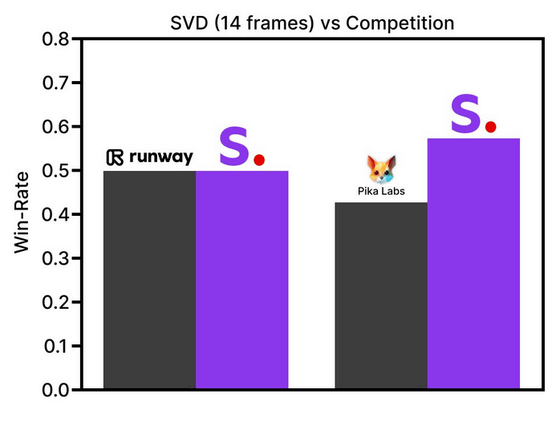
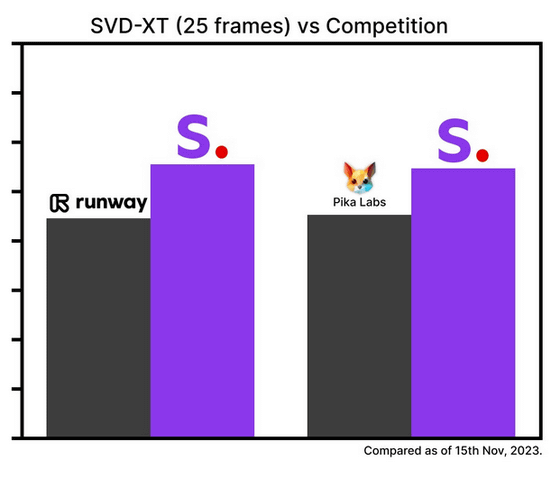
Stability AI đã công bố biểu đồ thanh dưới đây như một kết quả của việc so sánh đánh giá của người dùng về chất lượng video (trục dọc) với GEN-2 của Runway Research và PikaLabs của pika.art.
Trong trường hợp của Stable Video Diffusion (màu tím) có thể tạo ra 14 khung hình, nó trông như thế này.
Trường hợp của Stable Video Diffusion XT (màu tím), có thể tạo ra 25 khung hình, được hiển thị dưới đây.
Stability AI cho biết, 'Chúng tôi rất vui mừng khi thêm Stable Video Diffusion vào dải sản phẩm đa dạng của mình. Danh mục của Stability AI, bao gồm hình ảnh, ngôn ngữ, âm thanh, 3D, code, và các chế độ khác, tận dụng tối đa sức mạnh của trí tưởng tượng con người.
Đó là minh chứng cho sứ mệnh của Stability AI trong việc chuyển biến mạnh mẽ.