Trong khi các nhà đầu tư đang chuẩn bị phản ứng mạnh mẽ sau sự kiện Sam Altman bị loại bỏ một cách không lễ độ từ OpenAI và Altman đang lên kế hoạch trở lại công ty, các thành viên của nhóm Superalignment của OpenAI đã chăm chỉ tập trung vào vấn đề làm thế nào để kiểm soát AI thông minh hơn con người.
Ít nhất, đó là ấn tượng mà họ muốn tạo ra.
Tuần này, tôi đã tham gia cuộc gọi với ba thành viên của nhóm Superalignment — Collin Burns, Pavel Izmailov và Leopold Aschenbrenner — những người đang có mặt tại New Orleans tại NeurIPS, hội nghị học máy hàng năm, để trình bày công trình mới nhất của OpenAI về việc đảm bảo các hệ thống AI hoạt động như ý định.
OpenAI đã thành lập nhóm Superalignment vào tháng Bảy để phát triển cách thức điều khiển, quản lý và điều hành các hệ thống AI “siêu thông minh” — tức là, các hệ thống lý thuyết có trí tuệ vượt xa con người.
“Hiện nay, chúng tôi có thể căn chỉnh các mô hình kém thông minh hơn chúng tôi, hoặc có lẽ ở mức độ trí tuệ ngang bằng con người là tối đa,” Burns nói. “Việc căn chỉnh một mô hình thực sự thông minh hơn chúng tôi là điều khó hiểu hơn nhiều — làm thế nào chúng ta có thể làm được điều đó?”
Nỗ lực Superalignment được lãnh đạo bởi đồng sáng lập và giám đốc khoa học của OpenAI, Ilya Sutskever, điều này không gây ngạc nhiên vào tháng Bảy — nhưng hiện nay lại trở nên đáng chú ý trong bối cảnh Sutskever là một trong những người đầu tiên đẩy mạnh việc sa thải Altman. Mặc dù một số báo cáo cho rằng Sutskever đang ở trong một “trạng thái lơ lửng” sau khi Altman trở lại, phòng truyền thông của OpenAI cho tôi biết rằng Sutskever vẫn — ít nhất là cho đến hôm nay — vẫn đang lãnh đạo nhóm Superalignment.
Superalignment là một chủ đề nhạy cảm trong cộng đồng nghiên cứu AI. Một số người cho rằng lĩnh vực phụ này xuất hiện quá sớm; những người khác lại ngụ ý rằng đó là một sự phân tâm.
Trong khi Altman đã mời gọi sự so sánh giữa OpenAI và Dự án Manhattan, thậm chí đã thành lập một nhóm để thăm dò các mô hình AI nhằm bảo vệ chống lại các rủi ro “thảm khốc,” bao gồm cả mối đe dọa hóa học và hạt nhân, một số chuyên gia nói rằng có ít bằng chứng cho thấy công nghệ của startup này sẽ sớm đạt được khả năng kết thúc thế giới, vượt trội hơn con người — hoặc có thể không bao giờ. Những tuyên bố về trí tuệ siêu phàm sắp xuất hiện, theo những chuyên gia này, chỉ nhằm mục đích cố ý thu hút sự chú ý và làm lệch hướng khỏi các vấn đề quy định AI cấp bách hiện nay, như định kiến thuật toán và xu hướng độc hại của AI.
Đáng chú ý, Sutskever dường như thực sự tin rằng AI — không phải riêng AI của OpenAI, mà là một hình thức nào đó của nó — có thể một ngày nào đó đặt ra mối đe dọa tồn vong. Ông được cho là đã đi xa đến mức đặt hàng và đốt một hình nộm bằng gỗ trong một sự kiện ngoại vi công ty để thể hiện cam kết của mình trong việc ngăn chặn AI gây hại cho nhân loại, và chỉ đạo một lượng đáng kể sức mạnh tính toán của OpenAI — 20% số chip máy tính hiện có — cho nghiên cứu của nhóm Superalignment.
“Tiến bộ AI gần đây đã diễn ra vô cùng nhanh chóng, và tôi có thể đảm bảo rằng nó không hề chậm lại,” Aschenbrenner nói. “Tôi nghĩ chúng ta sẽ sớm đạt được các hệ thống ở cấp độ con người, nhưng không dừng lại ở đó — chúng ta sẽ tiến lên đến các hệ thống siêu nhân … Vậy làm thế nào chúng ta căn chỉnh các hệ thống AI siêu nhân và làm cho chúng an toàn? Đó thực sự là một vấn đề của toàn nhân loại — có lẽ là vấn đề kỹ thuật chưa giải quyết quan trọng nhất của thời đại chúng ta.”
Hiện tại, nhóm Superalignment đang cố gắng xây dựng các khuôn khổ quản lý và kiểm soát có thể áp dụng tốt cho các hệ thống AI mạnh mẽ trong tương lai. Đó không phải là một nhiệm vụ đơn giản, xét đến việc định nghĩa “siêu trí tuệ” — và liệu một hệ thống AI cụ thể đã đạt được nó hay chưa — là đề tài của cuộc tranh luận sôi nổi. Nhưng phương pháp mà nhóm đã chọn cho đến nay bao gồm sử dụng một mô hình AI yếu hơn, kém tinh vi (ví dụ: GPT-2) để hướng dẫn một mô hình tiên tiến hơn, tinh vi hơn (GPT-4) theo những hướng mong muốn — và tránh những hướng không mong muốn.
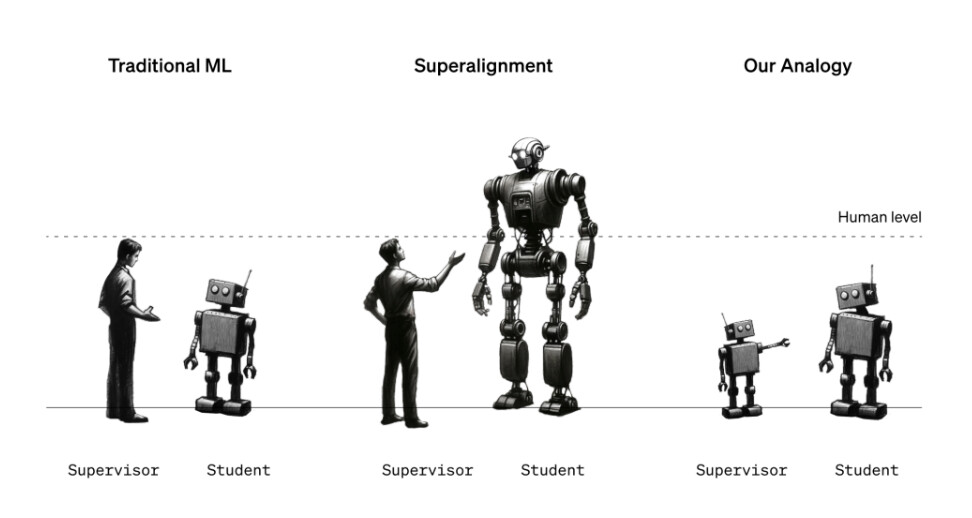
“Nhiều điều chúng tôi đang cố gắng làm là hướng dẫn một mô hình phải làm gì và đảm bảo nó sẽ thực hiện điều đó,” Burns nói. “Làm thế nào để chúng ta khiến một mô hình tuân theo hướng dẫn và chỉ giúp đỡ những điều đúng đắn, không bịa đặt? Làm thế nào để chúng ta khiến một mô hình cho chúng ta biết liệu mã lệnh mà nó tạo ra có an toàn hay là hành vi quá đáng? Đây là những loại nhiệm vụ mà chúng tôi muốn có thể thực hiện với nghiên cứu của mình.”
Nhưng đợi đã, bạn có thể nói — việc AI hướng dẫn AI có liên quan gì đến việc ngăn chặn AI đe dọa nhân loại? Thực ra, đó là một phép ẩn dụ: Mô hình yếu được coi là người giám sát thay thế cho con người trong khi mô hình mạnh đại diện cho AI siêu thông minh. Giống như con người có thể không hiểu được hết tất cả các phức tạp và tinh tế của hệ thống AI siêu thông minh, mô hình yếu không thể “hiểu” hết tất cả những phức tạp và tinh tế của mô hình mạnh — làm cho cấu hình này hữu ích để chứng minh giả thuyết về superalignment, theo nhóm Superalignment.
“Bạn có thể nghĩ về một học sinh lớp sáu đang cố gắng giám sát một sinh viên đại học,” Izmailov giải thích. “Giả sử học sinh lớp sáu đang cố gắng chỉ dẫn sinh viên đại học về một nhiệm vụ mà anh ta biết cách giải quyết… Mặc dù sự giám sát từ học sinh lớp sáu có thể có sai sót trong chi tiết, nhưng hy vọng rằng sinh viên đại học sẽ hiểu được ý chính và có thể thực hiện nhiệm vụ tốt hơn người giám sát.”
Trong cấu hình của nhóm Superalignment, một mô hình yếu được tinh chỉnh cho một nhiệm vụ cụ thể tạo ra nhãn được sử dụng để “giao tiếp” những ý chính của nhiệm vụ đó với mô hình mạnh. Với những nhãn này, mô hình mạnh có thể tổng quát hóa đúng hoặc sai một cách tương đối theo ý định của mô hình yếu — ngay cả khi nhãn của mô hình yếu chứa lỗi và định kiến, nhóm nghiên cứu đã phát hiện.
Phương pháp mô hình yếu-mạnh này thậm chí có thể dẫn đến đột phá trong lĩnh vực ảo tưởng, theo nhóm.
“Ảo tưởng (Hallucinations) thực sự rất thú vị, bởi vì bên trong, mô hình thực sự biết liệu thứ nó đang nói là sự thật hay hư cấu,” Aschenbrenner nói. “Nhưng cách mà những mô hình này được huấn luyện ngày nay, người giám sát con người thưởng cho chúng ‘ngón cái lên,’ ‘ngón cái xuống’ cho những gì chúng nói. Vì vậy, đôi khi, một cách không cố ý, con người thưởng cho mô hình vì nói những điều sai trái hoặc những điều mà mô hình thực sự không biết về và như vậy. Nếu chúng tôi thành công trong nghiên cứu của mình, chúng tôi nên phát triển các kỹ thuật nơi chúng ta có thể cơ bản triệu hồi kiến thức của mô hình và chúng tôi có thể áp dụng việc triệu hồi đó để xác định điều gì là sự thật hay hư cấu và sử dụng điều này để giảm bớt ảo tưởng.”
Nhưng sự so sánh này không hoàn hảo. Vì vậy, OpenAI muốn thu hút ý tưởng từ cộng đồng.
Với mục đích đó, OpenAI đang khởi xướng một chương trình cấp vốn trị giá 10 triệu đô la để hỗ trợ nghiên cứu kỹ thuật về căn chỉnh siêu trí tuệ, phần nào của nguồn vốn sẽ được dành riêng cho các phòng thí nghiệm học thuật, tổ chức phi lợi nhuận, các nhà nghiên cứu cá nhân và sinh viên sau đại học. OpenAI cũng dự định tổ chức một hội nghị học thuật về superalignment vào đầu năm 2025, nơi họ sẽ chia sẻ và quảng bá công trình của các ứng cử viên giải thưởng superalignment.
Thật tò mò, một phần nguồn vốn cho chương trình cấp vốn sẽ đến từ cựu CEO và chủ tịch Google, Eric Schmidt. Schmidt — một người ủng hộ nhiệt thành của Altman — đang nhanh chóng trở thành biểu tượng cho sự bi quan về AI, khẳng định sự xuất hiện của các hệ thống AI nguy hiểm đang đến gần và cho rằng các nhà quản lý không đang làm đủ để chuẩn bị. Điều này không hoàn toàn xuất phát từ lòng nhân ái — các báo cáo trên Protocol và Wired lưu ý rằng Schmidt, một nhà đầu tư AI tích cực, sẽ được hưởng lợi lớn về mặt thương mại nếu chính phủ Hoa Kỳ triển khai bản vẽ đề xuất của ông để tăng cường nghiên cứu AI.
Do đó, khoản đóng góp có thể được nhìn nhận như một hành động tín hiệu đạo đức qua lăng kính hoài nghi. Tài sản cá nhân của Schmidt ước tính khoảng 24 tỷ đô la, và ông đã đầu tư hàng trăm triệu vào các dự án và quỹ AI khác, rõ ràng ít tập trung vào đạo đức hơn — bao gồm cả của chính mình.
Tất nhiên, Schmidt phủ nhận điều này.
“AI và các công nghệ mới nổi khác đang tái cấu trúc nền kinh tế và xã hội chúng ta,” ông nói trong một tuyên bố qua email. “Đảm bảo chúng phù hợp với các giá trị của con người là điều quan trọng, và tôi tự hào khi hỗ trợ [chương trình cấp vốn] mới của OpenAI để phát triển và kiểm soát AI một cách có trách nhiệm cho lợi ích công cộng.”
Thực sự, sự tham gia của một nhân vật có động cơ thương mại rõ ràng như vậy khiến người ta tự hỏi: Liệu nghiên cứu về superalignment của OpenAI cũng như nghiên cứu mà họ khuyến khích cộng đồng gửi đến hội nghị tương lai của họ sẽ được công bố để bất kỳ ai cũng có thể sử dụng theo ý muốn của họ?
Nhóm Superalignment đã đảm bảo với tôi rằng, vâng, cả nghiên cứu của OpenAI — bao gồm mã lệnh — và công trình của những người khác nhận được cấp vốn và giải thưởng từ OpenAI về công việc liên quan đến superalignment sẽ được chia sẻ công khai. Chúng tôi sẽ giữ lời hứa với công ty.
“Đóng góp không chỉ vào sự an toàn của các mô hình của chúng tôi mà còn là sự an toàn của các mô hình của các phòng thí nghiệm khác và AI tiên tiến nói chung là một phần của sứ mệnh của chúng tôi,” Aschenbrenner nói. “Đó thực sự là trọng tâm của sứ mệnh của chúng tôi trong việc xây dựng [AI] cho lợi ích của toàn bộ nhân loại, một cách an toàn. Và chúng tôi nghĩ rằng việc nghiên cứu này hoàn toàn cần thiết để làm cho nó có ích và an toàn.”
cre: techcrunch